方案一:利用紫金桥自定义点类型+调用紫金桥API
首先不管使用哪种方案都用到了紫金桥实时数据库的“点”,这里先介绍下“点”的概念。
“点”的概念
紫金桥实时数据库中的点是一个逻辑组合,包含很多参数,每一个参数描述该点的一个属性。举例说一下,比如关系数据库,其中有很多表,每一种表中会有若干字段,各字段会描述一种属性,这里的每一种表都可以看作为紫金桥实时数据库中的一种点类型,每一个字段可以看作为点类型的一种参数,而实际的每条记录就可以看作为用户定义的一个实际的点。
比如关系数据库中有一种表,是一个物理量的信息表,其中包含物理量的名称、测量值、报警高限、最小量程、最大量程等字段(当然关系数据库中一般少有这种表结构),并存有“压力、1.2Mpa、2Mpa、0MPa、3Mpa”这么一条记录,那么对应到紫金桥实时数据库中就是一种叫做“模拟I/O点”的点类型,该点类型具有DESC(点说明)、PV(测量值)、HI(报警高限)、EULO(最小量程)、EUHI(最大量程)等参数,并且用户实际定义压力点P,即P.DESC=“压力”、P.PV=1.2(一般要连接实际设备,显示现场实际值)、P.HI=2、P.EULO=0、P.EUHI=3。
换个角度,其实紫金桥实时数据库中的每一种点类型相当于C++中的一个类或者一个结构体,每一种点参数相当于C++中类或结构体的成员变量,而每一个实际定义的点就相当于C++中该类或结构的一个实际对象。
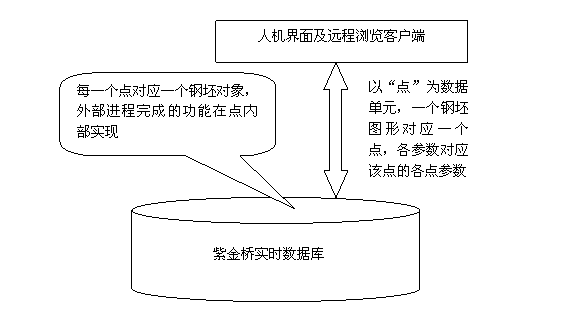
通过以上可以看出,紫金桥实时数据库是面向对象的,点是数据库处理数据的逻辑单元。利用紫金桥实时数据库中的点可以很方便的完成对物理量模型的管理。这里对于我们的钢坯模型,就可以通过“点”的方式进行管理。这里就要用到紫金桥自定义点类型。
紫金桥自定义点类型的方式
由于紫金桥实时数据库中没有针对“钢坯”的点类型,我们需要通过自定义点的方式添加一个“钢坯点”,这个点要包含钢坯的各个参数。
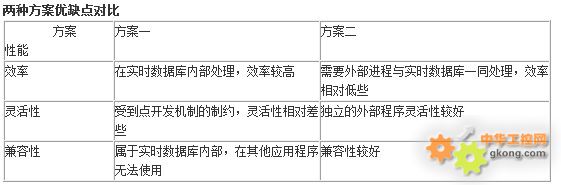
紫金桥自定义点的方式有两种,一种是在实时数据库开发系统中直接添加,无须编写程序;另一种是利用紫金桥数据库点开发包,通过编成的方式添加点类型。这两种方式互有优缺,前者比较简单,但灵活性稍差些;后者较为麻烦,但够灵活,可以根据具体情况选择。
调用紫金桥API
外部程序可以通过调用紫金桥API来修改实时数据库中的点,这里要注意点名及参数名必须一致。比如利用API接口中的SetDataByName(CStringList& list, CStringList& datList),就可以批量的修改点参数。
画面显示
利用紫金桥开发系统中的“动画连接”,将各点参数与对应的图元相关联,这样就可以完成外部程序对图形动画的控制。
结构框图
系统的结构框图如下:
方案二:利用自定义点类型
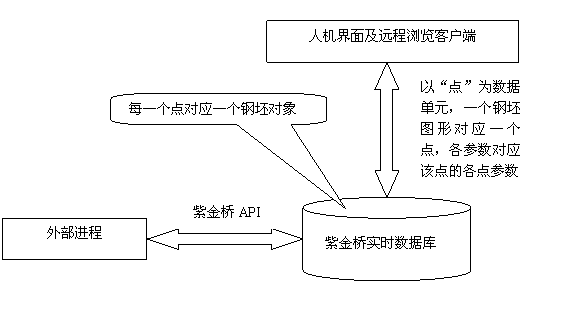
这里说的自定义点类型方式是指利用紫金桥点开发包自行开发。点开发包中不仅可以添加一些点参数形成新的数据库点类型,还可以完成对该点类型的数据处理。利用这种方法,可以将外部进程的数据处理等工作,直接嵌入到点类型中,能够处理钢坯的各参数信息,在内部完成参数的读写控制。
结构框图